
Pusheen will be your guide throughout this not-quite-so interactive tour of Latent Semantic Indexing, taking you on a simplified (yet exciting!) journey through the mind-boggling world of LSI. So keep all paws and wine glasses inside the vehicle at all times!
What is Latent Semantic Indexing (LSI)?

Latent Semantic Indexing sounds a lot more complicated than it actually is. In fact, if you break it down word for word, it immediately becomes a lot easier to understand.
Latent Semantic Indexing
The underlying meanings of words sorted into… things.
Okay, so the above definition is a little wobbly around the edges, but you get the point. Latent Semantic Indexing is the indexing of web pages based on the frequency of a whole variety of related keywords and phrases. They look at how the words on the page all relate to each other, rather than the densities of individual words, to find the underlying theme of the web page. This is a far more accurate way of determining the context, as copy writers before could simply just stuff the page full of keywords to rank for the keywords that they’re targeting for search without providing any further evidence that the page is actually relevant to those keywords. Search engines now have learnt to look at the bigger picture.
Things Not Strings!

You might have heard of this one before… Often muttered between those within the SEO community like some sort of code word to get a free gold star along with a lifetime membership of Moz Pro. Like “content is king“, “things not strings” has become yet another mantra for the SEO-obsessed and the mere utterance of the phrase will win you the heavily sought after “oohs” and “aahs” of your peers.
“Things not strings” refers to the shifted focus from keywords to topics in the evolution of SEO. Strings to mean the exact search queries typed into Google, and things meaning… well, things. Topics, themes, motifs, subject matters, etc, etc… Though Pusheen here loves nothing better than playing around with balls of string, search engines have grown up a bit in the past few years and know that its users care more about things… not strings.
Keyword Research for Semantic SEO
Synonyms are your new best friends. So retrieve your thesaurus from your highest bookshelf, my chums! (Or, y’know, visit thesaurus.com….) And use it as your roadmap to better content writing!
But your journey hasn’t stopped there, oh no! Semantic SEO isn’t just about how many variants of your main keywords you can use and how many times you can rephrase your key phrases in your headings. It’s about making sure that you are providing the user with a wealth of information. If something is written well, variants of keywords and other related subtopics should naturally occur within the content anyway. Typically in the past, SEO guys and gals would rank web pages for specific keywords through the redundant use of those same keywords over and over again on the page. Overuse of keywords can indicate badly written content; it’s written for search engines, not for users. Now you need to think about casting a wider net. You need to understand how users search and formulate target topics rather than target keywords and, if effective, you can start ranking for all sorts of bizarre long tail keywords relevant to your web page. Even if those keywords are nowhere to be found on your actual web page. LSI keywords are a totally different game.
What is Topic Modelling?
Topic modelling is literally modelling the topic of your page. Doing all that fun stuff with your keywords is just the tip of the iceberg. Even the distance between semantic keywords all play a part in the overall equation. You should also be using images that are relevant to your content and be alt tagging them appropriately within the context of your writing.
You need to explore the semantic connectivity between the entities mentioned on your web page. Take this for example:

Pusheen’s love for food is already quite a well-established fact on the internet, as is all of Pusheen’s favourite food. In fact, many of us use Pusheen stickers to represent how hungry we are when we are trying to share that important information with our friends on Facebook. So when you write a blog post about Pusheen, Google would expect you to at least mention how much Pusheen loves to eat. You may even expand into listing some of Pusheen’s favourites, like pizza, burger, pie, noodles… From Google’s perspective, it’s a little something like this: “Hey, this page is about Pusheen! From what I’ve seen of other pages about Pusheen, that cat sure loves her food… I should expect there’ll be plenty of mentions of pizza and cookies and all sorts!”
This is called co-occurrence.
So WTH are Co-Occurrence and Co-Citations?!
Co-nfusing. Ever heard of the Hummingbird? Basically, Google released a brand new algorithm in 2013 called Hummingbird, and it improved the search engine’s understanding of conversational and semantic search, allowing it to recognise relationships between entities (things). You can equate this game-changing event in SEO to Google learning a new language. And, like humans, it can take years to develop proficiency in a new language. Hummingbird brought about a completely revolutionary way of looking at the internet.

By recognising the semantic relationships between things, Google can produce search results with higher relevancy to its users. If a page about Apple (the brand) talks about Macs and iPhones and tech-y things, Google’s going to be pretty sure that the page isn’t about apple the fruit. As for co-citations, if Apple is frequently mentioned on web pages in regards to smartphones or computers, these mentions can be just as powerful as links to Apple’s website. Google will start recognising brand names in context to the rest of the page, relating brand names to things similar to how co-occurrence is relating things to other things. If your brand is frequently mentioned in regards to a topic, you’re establishing that your brand is an authority on that topic. And, in turn, your brand might start ranking better for search queries of that topic. Also, if a webpage is citing or linking to big authority websites, such as Wikipedia, as well as your website, it’s saying that there’s a semantic connection there between those websites and yours, so really you want your website to be running with the right crowd (the relevant crowd). It’s often likened to “link building without links”. Co-citation building :)
(Read more – Co-Citation and Co-Occurrence: What’s the Difference?)
Recent News of Google’s Fact Checking Algorithm to Rank Pages
So how does all this Latent Semantic Indexing stuff relate to the recent news of Google experimenting with a new fact checking algorithm to rank pages? Google have stated in the past that they want to create a better search engine that ranks pages based on trustworthiness and not just reputation. An algorithm that will detect any misinformation on a page and rank it lower so that Google doesn’t provide its users with incorrect information just because this web page has more links than that web page.
Google have been building an enormous database, known as the Knowledge Vault, using “fact checking” bots that autonomously travel around the internet collecting and merging information. This is basically what the whole co-occurrence thing is doing. Google isn’t God. Google doesn’t know everything. Google relies on crowd sourced data to develop its understanding of what things are and how they are connected to each other.
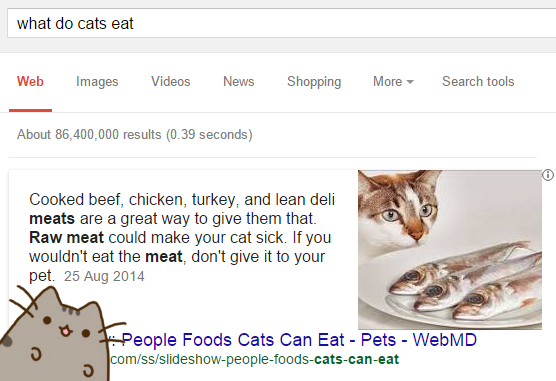
We can already see something like this with the Knowledge Graph when we search for things on Google. The difference between the Knowledge Graph and the Knowledge Vault is how the information is collected. As you can see in the above search example, Google knows that webmd.com is a pretty reliable source of information, so it displays information that it has collected through trusted websites like Wikipedia, etc, right there in the search results. However, Google’s Knowledge Vault is far more ambitious. It accumulates facts from all over the web, so rather than taking information directly from a trusted source, Knowledge Vault’s solution to finding what cats like to eat would be to find out what the internet has unanimously agreed upon in regards to what cats like to eat. From trustworthy and non-trustworthy websites alike.
Google hasn’t got round to learning much about Pusheen’s dietary preferences yet, it seems… But that doesn’t mean that Google doesn’t know anything about it at all! Google’s Knowledge Vault is said to be the future of search. Eventually, Knowledge Vault will power Google Search. It’s just a matter of time.
And what is this “Semantic Mark Up” I’ve heard so much about?
And finally…. schema! Semantic mark up, such as schema, gives us a way to semantically mark up our content, or structure our data (hence the whole “structured data” thing). Schema and other forms of semantic markup and structured data allows search engines to better understand things a little easier. e.g. “Hey, Google! This number isn’t just a random number. This number is a phone number. So please can you treat it like one.”
TL;DR

Things not strings. Stop obsessing over keywords. Users not search engines. Quality content. Topics not keywords. Blah blah blah. Yada yada yada.

Great article! How do you feel about future of LSI? At this point, it looks very advanced. However, I feel there is still room for improvement.
I feel like LSI is definitely the future of SEO, and will continue to become more and more essential to how we perceive SEO and develop strategies around it. This is evidenced in Google’s more recent announcement about RankBrain being the third most important signal in their ranking algorithm, and machine-learning becoming a bigger part of their search engine.
Hey Ria,\n\nThank you for your answer!\n\nYes, the power of LSI keywords is definitely yet to be seen. I recently read this article on SERoundtable (https://www.seroundtable.com/google-top-three-ranking-factors-21827.html) saying that content, links and RankBrain will matter the most in the future of SEO.\n\nActually, a former Googler said that machine-learning probably already is a part of Google algorithms indeed.\n\nRia, I wrote an article on LSI yesterday. Would you be interested in reading it and share your expert feedback on it?\n\nHere’s the link: http://niksto.com/lsi-keywords/\n\nThanks in advance,\n\nNick
You really did your research. Great article! I’ve shared it on inbound.org ;)
LSI is stand for Latest Semantic Indexing. LSI is process for index for your content in search engine database and how it’s retrieved in search result terms.