
Welcome to the fourth installment of The Noob’s Guide to Twython, where we’re playing around with the Twitter API with Python, using the Twython module. These tutorials are aimed at those who are perhaps learning to code for the first time, or have only a beginner’s knowledge of Python. If you’re looking for some advanced stuff, you’ve come to the wrong place!
This tutorial assumes that you already know how to set up your Twython for the first time!
It doesn’t need to be said that Followers are, and should be, the driving force behind your social success on Twitter. You need to make your Followers feel special for Following you. And you need to get as much information about them as possible, so you can analyse your follower demographics for further analysis and targeting. So you can find out exactly how you can make them feel even more special! And feel that following you is worthwhile….
But before you can do any of that, you first need to get some idea of who your followers are. So let’s start on the basics!
Getting a list of a user’s Twitter Followers:
Sometimes it’s handy to quickly get a list of all your Twitter Followers, or all the Followers of a Twitter account, all in one simple list. With Twython, it’s super easy to do that. So let’s quickly check out our first step toward our Follower Analysis program!
from twython import Twython, TwythonError
# Let's import the datetime module!
import datetime
app_key = "YOUR_APP_KEY"
app_secret = "YOUR_APP_SECRET"
oauth_token = "YOUR_OAUTH_TOKEN"
oauth_token_secret = "YOUR_OAUTH_TOKEN_SECRET"
# This should be all on one line:
twitter = Twython(app_key,app_secret,oauth_token,oauth_token_secret)
# Creating an empty list, ready for our followers
followers = []
# Getting today's date
datestamp = datetime.datetime.now().strftime("%Y-%m-%d")
# Asking for the username to get their followers
username = raw_input("Retrieve Follower list of: ")
# This is to go through paginated results
next_cursor = -1
while(next_cursor):
# Getting the user's followers (should all be 1 line)
get_followers = twitter.get_followers_list(screen_name=username,count=200,cursor=next_cursor)
# For each user returned from our get_followers
for follower in get_followers["users"]:
# Add their screen name to our followers list
followers.append(follower["screen_name"].encode("utf-8"))
next_cursor = get_followers["next_cursor"]
# Create or open a new .txt file
followers_text = open(username+"-"+datestamp+".txt","a")
# Write the first "title" line and followers list to the .txt
# Should all be one (very long) line:
followers_text.write("%s has %s followers (%s):
" % (str(username),str(len(followers)),str(datestamp))+"
".join(followers))
# Close the .txt file
followers_text.close()
Creating a Follower List:
So. Before you hurt yourself… let’s break it down:
followers = []
datestamp = datetime.datetime.now().strftime("%Y-%m-%d")
username = raw_input("Retrieve Follower list of: ")
next_cursor = -1
Setting our initial variables. Line by line:
- We’re going to need to create an empty list to store our followers, once we’ve gotten them.
- We’re pulling in the datetime module for this, because we’re going to want to get today’s date so that we can label our files correctly, and know when the list was taken. So we’re getting the .now() which is the current date/time. But we need to format how our datestamp is printed using strftime() so we only display the year (%Y), the month (%m) and the date (%d). And separate these numbers with a hyphen so it’s easier to read. So today’s date should say if you were to try to print the datestamp: 2014-6-27.
- raw_input() prompts the user for a string, then stores that string as the variable. So whatever username we type when the program puts “Retrieve Follower list of: ” will from now be known as username.
- The results will be returned paginated. -1 is the default first page.
while(next_cursor):
# Should all be one (very long) line:
get_followers = twitter.get_followers_list(screen_name=username,count=200,cursor=next_cursor)
for follower in get_followers["users"]:
followers.append(follower["screen_name"].encode("utf-8"))
next_cursor = get_followers["next_cursor"]
So what are we doing here? We are telling Twitter to return us a count of 200 followers per “page” that belong to the username (that we will enter when the program asks us. This way the username isn’t hard-coded in. We can change the username every time we run the program).
For every follower that gets returned from get_followers‘ users, we want the program to add that follower’s screen name (i.e. @username, not their Display Name) to our list of followers and encode it in UTF-8, so it can display every character as it should be displayed. Then we move onto the “next page” until there’s no more followers to add to the list!
Spitting it out into a handy text file!
This is the easy part! We just want to shove our followers list into a .txt file, for easy reference later maybe.
followers_text = open(username+"-"+datestamp+".txt","a")
# This should all be on one (super-duper long) line:
followers_text.write(%s has %s followers (%s):
" % (str(username),str(len(followers)),str(datestamp))+"
".join(followers))
followers_text.close()
First, let’s just create (or open if it already exists in the folder) a new .txt file. We want to name the file the username we’re trying to get the followers of followed by the date. So if we were to create a new file today of Silkstream’s followers, the file would be called:
silkstreamnet-2014-06-27.txt
So that’s pretty handy. And it means that if we were to generate a new .txt file each week of all the Twitter users we’re tracking, they’d all be ordered chronologically in our directory. Awesome.
Now for the actual creation of the file’s text content. We can use followers_text.write() to write whatever text we want in the file. In this case, we want to just put a little text title at the top to say:
silkstreamnet has 147 followers (2014-06-27):
%s is like a string placeholder. So where there are three “string placeholders”, we’ll define in a minute what we actually want to insert into there.
means “new line”. So after we’ve put our little text title at the top, we want to start our actual list of followers two lines down, because we’ve put
twice.
So now let’s tell our program what we want to insert into our title! Instead of those placeholders we want to insert our username, the length of the followers list (that’s how many followers that user has) converted to a string, and the date converted to a string.
And then that’s when we want to write out the usernames of all the followers in our list, joining each one with a new line so when they’re written to the text file, there’ll be one username per line.
Finally, we want to remember to close the text file that we had open to save our changes. You should now see the .txt file in the directory you’re working out of! Perfect.
How your final .txt program should look:
from twython import Twython, TwythonError
import datetime
app_key = "YOUR_APP_KEY"
app_secret = "YOUR_APP_SECRET"
oauth_token = "YOUR_OAUTH_TOKEN"
oauth_token_secret = "YOUR_OAUTH_TOKEN_SECRET"
twitter = Twython(app_key,app_secret,oauth_token,oauth_token_secret)
followers = []
datestamp = datetime.datetime.now().strftime("%Y-%m-%d")
username = raw_input("Retrieve Follower list of: ")
next_cursor = -1
while(next_cursor):
get_followers = twitter.get_followers_list(screen_name=username,count=200,cursor=next_cursor)
for follower in get_followers["users"]:
followers.append(follower["screen_name"].encode("utf-8"))
next_cursor = get_followers["next_cursor"]
followers_text = open(username+"-"+datestamp+".txt","a")
followers_text.write(%s has %s followers (%s):
" % (str(username),str(len(followers)),str(datestamp))+"
".join(followers))
followers_text.close()
Now let’s try something a little more complicated…
Although sometimes you really do just want to get hold of a quick list of your followers for whatever reason, most of the time you’re going to want something a little more in depth than just a list of their usernames…
So let’s try creating a CSV spreadsheet file of your followers instead! This way we can add columns with different user details about our followers.
from twython import Twython, TwythonError
# Need to import csv now too!
import csv
import datetime
app_key = "YOUR_APP_KEY"
app_secret = "YOUR_APP_SECRET"
oauth_token = "YOUR_OAUTH_TOKEN"
oauth_token_secret = "YOUR_OAUTH_TOKEN_SECRET"
twitter = Twython(app_key,app_secret,oauth_token,oauth_token_secret)
# This time we want to make several lists!
names = []
usernames = []
ids = []
locations = []
follower_count = []
datestamp = datetime.datetime.now().strftime("%Y-%m-%d")
username = raw_input("Retrieve Follower list of: ")
next_cursor = -1
while(next_cursor):
get_followers = twitter.get_followers_list(screen_name=username,count=200,cursor=next_cursor)
for follower in get_followers["users"]:
# And add some more user details to its corresponding list
names.append(follower["name"].encode("utf-8"))
usernames.append(follower["screen_name"].encode("utf-8"))
ids.append(follower["id"])
locations.append(follower["location"].encode("utf-8"))
follower_count.append(follower["followers_count"])
next_cursor = get_followers["next_cursor"]
# Instead of creating a .txt we want to create a .csv!
open_csv = open(username+"-"+datestamp+".csv","wb")
# And write to it...
followers_csv = csv.writer(open_csv)
# Creating our top "title" row
names.insert(0,"@%s has %s followers (%s)" % (str(username),str(len(followers)),str(datestamp)))
usernames.insert(0,"")
ids.insert(0,"")
locations.insert(0,"")
follower_count.insert(0,"")
# Give each column its own title
names.insert(1,"
Display Name
")
usernames.insert(1,"
Username (@)
")
ids.insert(1,"
User ID
")
locations.insert(1,"
Location
")
follower_count.insert(1,"
# of their Followers
")
# Merge all our lists together so that they line up
rows = zip(names,usernames,ids,locations,follower_count)
# Write each row one-by-one to our spreadsheet
for row in rows:
followers_csv.writerow(row)
# Save and close our csv spreadsheet
open_csv.close()
Creating our lists for all the followers’ details
We can get a lot more details about each follower, but let’s just start with 5 to keep things simple:
- Display Names – The name that they go by (which they can change)
- Usernames – Their @username (which they can’t change)
- IDs – The User ID number of the follower
- Locations – Where they have their location set to on their profile
- Follower Count – How many followers they currently have themselves
So we need to create an empty list for each of those user characteristics, so that we can store those details that we’ll get in a minute.
names = []
usernames = []
ids = []
locations = []
follower_count = []
Next we’re going to do what we did with our .txt file, but we need to get the other user details too and, like how we appended them to our followers list before, we’re going to chuck those details into their own lists.
while(next_cursor):
get_followers = twitter.get_followers_list(screen_name=username,count=200,cursor=next_cursor)
for follower in get_followers["users"]:
names.append(follower["name"].encode("utf-8"))
usernames.append(follower["screen_name"].encode("utf-8"))
ids.append(follower["id"])
locations.append(follower["location"].encode("utf-8"))
follower_count.append(follower["followers_count"])
next_cursor = get_followers["next_cursor"]
So for each follower we get back from get_followers‘ users we append the follower name to the names list, the follower screen_name to our usernames list, the follower id to ids, etc.
Making our CSV spreadsheet look all pretty
But certainly not our code…. >.<
open_csv = open(username+"-"+datestamp+".csv","wb")
followers_csv = csv.writer(open_csv)
# Creating our top "title" row
names.insert(0,"@%s has %s followers (%s)" % (str(username),str(len(followers)),str(datestamp)))
usernames.insert(0,"")
ids.insert(0,"")
locations.insert(0,"")
follower_count.insert(0,"")
# Give each column its own title
names.insert(1,"
Display Name
")
usernames.insert(1,"
Username (@)
")
ids.insert(1,"
User ID
")
locations.insert(1,"
Location
")
follower_count.insert(1,"
# of their Followers
")
So, as we did with the text file, we need to open (or create if it doesn’t already exist in the working directory) a .csv file. We name it exactly how we named the text file before, so the filename will be
username-YY-MM-DD.csv
followers_csv = csv.writer(open_csv) means that from now, we will refer to the csv file we’re writing to as followers_csv in the csv writer.
So let’s create our top title row, with the very first cell in the very first row telling us how many followers our specified user has, accompanied with our date. Like we had in the top line of our text file. So we’re telling our program to insert that string in the names list as the very first item in the list (which is [0] as indexes start as 0 and not 1, remember?). The rest we’ll fill in with an empty string just to fill in the row’s blanks. The method’s a bit unimaginative to be honest, but it will do.
So if our chosen username is silkstreamnet, the top line should read:
@silkstreamnet has 147 followers (2014-06-27)
Next, we want to do exactly the same thing with our second row (or [1] in each list) but this time we want to insert the column titles for each list.
So in this example, we’ve chosen to title each column on the second row:
- Display Name
- Username (@)
- User ID
- Location
- # of their Followers
Using
immediately before and after each title, we can pad out the title row a bit to make it stand out a bit more.
Shoving our followers’ details in row-by-row…
rows = zip(names,usernames,ids,locations,follower_count)
for row in rows:
followers_csv.writerow(row)
open_csv.close()
Let’s first understand what zip does. It literally “zips” lists together. For example:
Say we have two lists:
list1 = [“1″,”2″,”3”]
list2 = [“a”,”b”,”c”]
If we zipped them both together with zip(list1,list2), we would get:
[(“1″,”a”),(“2″,”b”),(“3″,”c”)]
So in the zip’s parameters, we give it our lists that we want zipped (all of them in this case), and we’re calling this rows. Which makes sense as we’re going to fill our rows with this information. And by zipping the lists in this way, we’ve bunched the followers’ details up so each follower has almost like a list of their own containing only their details.
Next we’re saying that for each row in rows, print that row to its own row. That’s a lot of rows!
But ultimately, every follower (and all of their details that we’ve requested) will be written to its own row.
Row. By. Row.
And of course, don’t forget to close your .csv file when you’re done writing to it ;]
The final code should look something like this…
from twython import Twython, TwythonError
import csv
import datetime
app_key = "YOUR_APP_KEY"
app_secret = "YOUR_APP_SECRET"
oauth_token = "YOUR_OAUTH_TOKEN"
oauth_token_secret = "YOUR_OAUTH_TOKEN_SECRET"
twitter = Twython(app_key,app_secret,oauth_token,oauth_token_secret)
names = []
usernames = []
ids = []
locations = []
follower_count = []
datestamp = datetime.datetime.now().strftime("%Y-%m-%d")
username = raw_input("Retrieve Follower list of: ")
next_cursor = -1
while(next_cursor):
get_followers = twitter.get_followers_list(screen_name=username,count=200,cursor=next_cursor)
for follower in get_followers["users"]:
names.append(follower["name"].encode("utf-8"))
usernames.append(follower["screen_name"].encode("utf-8"))
ids.append(follower["id"])
locations.append(follower["location"].encode("utf-8"))
follower_count.append(follower["followers_count"])
next_cursor = get_followers["next_cursor"]
open_csv = open(username+"-"+datestamp+".csv","wb")
followers_csv = csv.writer(open_csv)
names.insert(0,"@%s has %s followers (%s)" % (str(username),str(len(followers)),str(datestamp)))
usernames.insert(0,"")
ids.insert(0,"")
locations.insert(0,"")
follower_count.insert(0,"")
names.insert(1,"
Display Name
")
usernames.insert(1,"
Username (@)
")
ids.insert(1,"
User ID
")
locations.insert(1,"
Location
")
follower_count.insert(1,"
# of their Followers
")
rows = zip(names,usernames,ids,locations,follower_count)
for row in rows:
followers_csv.writerow(row)
open_csv.close()
Run your program!
Type the username of who you want to get a follower list for.
![]()
Now check in the directory that you’re program is saved in, and your newly created (or newly edited) file should be sitting in there too!
![]()
Try opening it!
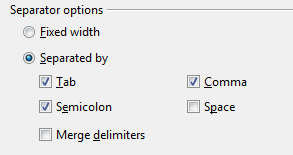
By default, your separator options should be set like it is in the screenshot above. Usually, if Comma is unchecked, you’re going to get weird formatting and everything’s going to be in a single column, separated by commas. It’s not called Comma Separated Values for nothing!
Your Followers Spreadsheet! Yay! It’s alive!
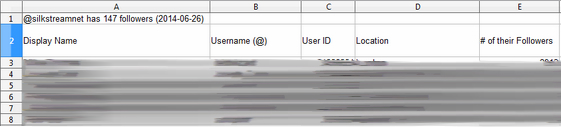
Yours should look like the screenshot above. Obviously in our screen shot we’ve blurred our followers. Even though it’s public data. But y’know…
And you can even upload it onto Google Docs so you can have it available online!
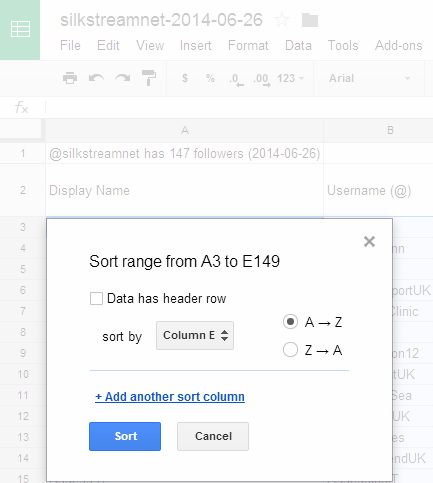
Then you can do all sorts of cool things. Like sorting your spreadsheet of followers in descending order of influence, ranking those with the most followers themselves higher on your list (Z-A, and in our example our follower count is in Column E). Or you could sort your followers alphabetically, or by ID, or even by location!
By no means is this the prettiest of code. I know this is definitely not the cleanest way to do this. I could probably condense down huge chunks of code. But I’m still a Python/Twython Noob, and you’re just a Python/Twython Noob (no offense) so I’m just trying to focus more on readability than how “clean” something is. It should still all function the same. Just probably not as written efficiently as it could be…
Great blog! I can program some perl and bash, but python is new to me.\nCant wait to learn howto post pictures! \nI have a tree website and want to make tree tutorials with twitter inclusing photos, so cant wait to find out howto tweet with images. \nThanks for the great blog!
Hi Hanscees!
Thank you for the lovely comment. So glad you’re enjoying the tutorial.
Once you’ve learnt the basic Twython usage of updating statuses, updating statuses with images attached really isn’t too difficult.
In fact, if you check back this Friday, I may publish a new tutorial on how to do just this (with extra features) especially for you ;)
Happy Coding!
EDIT: Your tutorial’s up now! :D
Wonderful!
So great to discover Twython with your tutos !
By testing this part, i have a “Twitter API returned a 429 (Too Many Requests), Rate limit exceeded”…
Maybe we have to put a time limite like “time.sleep(60)” ?
Hope this noob-tuto-serie will never stop :)
Just found this awesome tutorial. Great, I’m just trying to use it on Python 3, so i put
username = input("Retrieve Follower list of: ")instead of
username = raw_input("Retrieve Follower list of: ")Seems to work, but I get this error:
Traceback (most recent call last):
File “followers.py”, line 43, in followers_text.write((str(username),str(len(followers)),str(datestamp))+”\n”.join(followers))
TypeError: sequence item 0: expected str instance, bytes found
Any suggestions?
thank you
Love these tutorials, thanks so much for writing them!
I am trying to combine your retweet and follow tutorial, so it searches for a keyword then retweets and follows that user.
Is there a way to refer to the tweets it tweets to follow those users or would I have to load my last 20 (or what ever count is) and somehow extract the people to follow?
Many Thanks for any pointers :)
Hiya Henry,
Thanks for your kind words!! :D
So what you want to do essentially breaks down into two parts: getting the tweet’s username, then following them.
Take a look at grabbing the screen_name from your tweet in search_results, and beneath your retweet() line use the create_friendship() function to follow the user.
That should be the easiest way of doing it.
Take a look at:
https://dev.twitter.com/rest/reference/get/search/tweets
https://dev.twitter.com/rest/reference/post/friendships/create
Good luck
Hey Ria, awesome script and tutorial! I was just testing it out and discovered one error:\n\n
\nTraceback (most recent call last):\n File "./test.py", line 51, in \n names.insert(0,"@%s has %s followers (%s)" % (str(username),str(len(followers)),str(datestamp)))\nNameError: name 'followers' is not defined\n\n\nI figured it out and made an update to this line just in case you wanted to fix the tutorial:\n\n\n# Creating our top "title" row\nnames.insert(0,"@%s has %s followers (%s)" % (str(username),str(len(follower_count)),str(datestamp)))\n\n\nstr(len(followers))should bestr(len(follower_count))\n\nThanks!Thanks for pointing that out, Shawn!
I also found that the error came up:
TypeError: a bytes-like object is required, not ‘str’
I resolved this by changing line 34:
open_csv = open(username+”-“+datestamp+”.csv”,”wb”)
to:
open_csv = open(username+”-“+datestamp+”.csv”,”w”)
i.e. Just removing ‘b’ from ‘wb’.
Hope this helps someone!